Is the P=NP Problem an NP Problem?

What I’m going to say is going to be unpopular, but I cannot reconcile my own well-being without giving you an answer to this problem from my perspective.
My only reason for reluctantly writing this, knowing what kind of reaction I could receive is, because I abhor that some of the best minds on our planet are occupying themselves with this problem. It pains me to no end to see humanity squandering its power for a problem that, as it is currently framed, is unanswerable. It goes further than this though. There will come a time when questions such as this one will be cast upon the junk heap of humanity’s growth throughout history. It will take its rightful place along such ideas as phrenology.
Here’s why I say this:
The problem is firmly and completely embedded in Functional Reductionism. I say this, because the problem’s framing requires us to peel away the contextual embedding of the problems for which it is supposed to clarify.
This is just one of its problems. Here’s another:
Since the data for this problem (and those like it) are themselves algorithms, they are compelled to be functionally reduced versions of mind problem solving (varying types of heuristics and decision problems) which reduces the problem’s causal domain and its universe of discourse even further. How can a specification based upon functionally reduced data be again used as data for the problem’s solution in the first place?
That means that this problem has no independent existence nor causal efficacy. Everywhere I have looked at this problem, the definitions of NP-Hard and NP-Complete do not lead to proving anything useful. We cannot ‘generalise’ the mind by reducing it to some metric of complexity. Complexity is also not how the universe works as Occam’s Razor[1] shows.
I am prepared to defend my position should someone have the metal to test me on this. Another thing: I wish I could have left this alone, but we all need to wake up to this nonsense.
[1] http://bit.ly/2GHbRkW How Occam’s Razor Works
[Quora] http://bit.ly/2EuRdP3
Getting Hypertension About Hyperreals
 (Links below)
(Links below)
This system is quite interesting if we allow ourselves to talk about the qualities of infinite sets as if we can know their character completely. The problem is, any discussion of an infinite set includes their definition which MAY NOT be the same as any characterisation which they may actually have.
Also, and more importantly, interiority as well as exteriority are accessible without the use of this system. These ‘Hyperreals’ are an ontological approach to epistemology via characteristics/properties we cannot really know. There can be no both true and verifiable validity claim in this system.
https://www.youtube.com/watch?v=rJWe1BunlXI (Part1)
https://www.youtube.com/watch?v=jBmJWEQTl1w (Part2)
Is Mathematics Or Philosophy More Fundamental?

Is Mathematics Or Philosophy More Fundamental?
Answer: Philosophy is more fundamental than mathematics.
This is changing, but mathematics is incapable at this time of comprehensively describing epistemology, whereas, philosophy can.
Hence; mathematics is restrained to pure ontology. It does not reach far enough into the universe to distinguish anything other than ontologies. This will change soon. I am working on exactly this problem. See http://mathematica-universalis.com for more information on my work. (I’m not selling anything on this site.)
Also, mathematics cannot be done without expressing some kind of philosophy to underlie any axioms which it needs to function.
PROOF:
Implication is a ‘given’ in mathematics. It assumes a relation which we call implication. Mathematics certainly ‘consumes’ them as a means to create inferences, but the inference form, the antecedent, and the consequent are implicit axioms based upon an underlying metaphysics.
Ergo: philosophy is more general and universal than mathematics.
Often epistemology is considered separate from metaphysics, but that is incorrect, because you cannot answer questions as to ‘How do we know?” without an underlying metaphysical framework within which such a question and answer can be considered.
HUD Fly-by Test

Don’t take this as an actual knowledge representation; rather, simply a simulation of one. I’m working out the colour, transparent/translucent, camera movements, and other technical issues.
In any case you may find it interesting.
The real representations are coming soon.
A New Kind of Knowledge Representation Is Coming to Be!

The project is now coming to conclusion (finally). In this video I show an example knowledge molecule being ‘examined’ by the knowledge representation.
I’ve hidden the other actors in this demonstration and have simplified the instrumentation to preserve my priority on my work.
Be patient! It won’t be long now… I have the theoretical underpinnings already behind me. Now it’s only about the representation of that work.
Obfuscation In A ‘Nut’ Shell





Distinctions that are no differences, are incomplete, or are in discord.
In knowledge representation these ‘impurities’ (artificiality) and their influence are made easy to see.
In groks you will see them as obfuscation fields. That means darkening and/or inversion dynamics. The term refers to the visual representation of an obfuscated field, and can also be represented as dark and/or inverted movements of a field or group. I concentrate more on the dark versions here and will consider the inversions (examples of lying) in a future post.
They bring dynamics that are manipulative, artificial, or non-relevant into the knowledge representation. Their dynamic signatures make them stand out out like a sore thumb.
Cymatic images reveal these dynamics too. There are multiple vortexes, each with their own semantic contribution to the overall meaning to a knowledge molecule or group.
Here is an example of a snow flake (seen below) https://www.flickr.com/photos/13084997@N03/12642300973/in/album-72157625678493236/
From Linden Gledhill.
Note that not all vortexes are continuous through the ‘bodies’ of the molecules they participate in. Also, in order to correctly visualize what I’m saying, one must realize that the cymatic images are split expressions. That means to see the relationship, you must add the missing elements which are hinted at by the image.
Every cymatic image is a cut through the dynamics it represents.
We are in effect seeing portions of something whole. Whole parts are dissected necessarily, because the surface of expression is limited to a ‘slice’ through the complete molecule.
(Only the two images marked ‘heurist.com’ are my own! The other images are only meant as approximations to aid in the understanding of my work.)
Men And Their Semantics – Turning Meaning into Legos

Semantically speaking: Does meaning structure unite languages?
This work is a dead end waiting to happen. Of course it will attract much interest, money, and perhaps even yield new insights into the commonality of language, but there’s better ways to get there.
What’s even more sad is that they, who should know better, will see my intentions in making this clear as destructive criticism instead of a siren warning regarding research governed/originating through a false paradigm. These people cannot see or overlook the costs humanity pays for the misunderstandings research like this causes and is based upon.
It’s even worse in the field of genetic engineering with their chimera research. The people wasting public money funding this research need to be gotten under control again.
I don’t want to criticize the researcher’s intentions. It’s their framing and methodology that I see as primitive, naive, and incomplete.
I’m not judging who they are nor their ends; rather, their means of getting there.
“Quantification” is exactly the wrong way to ‘measure/compare semantics; not to mention “partitioning” them!
1) The value in this investigation that they propose is to extrapolate and interpolate ontology. Semantics are more than ontology. They possess a complete metaphysics which includes their epistemology.
2) You cannot quantify qualities, because you reduce the investigation to measurement; which itself imposes meaning upon the meaning you wish to measure. Semantics, in their true form, are relations and are non-physical and non-reducible.
3) Notice also, partitioning is imposed upon the semantics (to make them ‘measurable/comparable’). If you compare semantics in such a way then you only get answers in terms of your investigation/ontology.
4) The better way is to leave the semantics as they are! Don’t classify them! Learn how they are related. Then you will know how they are compared.
There’s more to say, but I think you get the idea… ask me if you want clarification…
Ontology: Compelling and ‘Rich’

Ontologies are surfaces… even if ‘rich’. (link)
Ontology: Compelling and ‘Rich’
They are only surfaces, but they seem to provide you with depth.
This exquisite video shows how the representation of knowledge is ripe for a revolution. I’ve written about this in depth in other places so I won’t bore you with the details here unless you ask me in the comments below.
Stay tuned! I’m behind in my schedule (work load), but I’m getting very close just the same. I will publish here and elsewhere.
I’m going to use this video (and others like it) to explain why ontologies are not sufficient to represent knowledge.
Soon everyone will acknowledge this fact and claim they’ve been saying it all along! (In spite of the many thousands of papers and books obsessively claiming the opposite!!!) They do not know that how dangerous that claim is going to be. Our future will be equipped with the ability to determine if such claims are true or not. That’s some of the reason I do what I do.
#KnowledgeRepresentation #BigData #Semantics #Metaphysics #Ontology
#Knowledge #Wisdom #Understanding #Insight #Learning #MathesisUniversalis #MathesisGeneralis #PhilosophiaUniversalis #PhilosophiaGeneralis #ScientiaUniversalis #ScientiaGeneralis
Coming Soon To A World Near You
 Coming Soon To A World Near You
Coming Soon To A World Near You
The time is coming when we will exchange massive amounts of knowledge between us without any corporation standing in between.
My life’s work is dedicated to this vision and I’m actually carrying it out right in front of you!
We will not only create and share our books, documents, web sites, search results, and media with each other – we will be sharing their conceptual landscapes.
3D Scientific Visualization with Blender

3D Scientific Visualization with Blender
It’s a book everyone in knowledge representation should at least know about. It has great tips and clarifications inside.
Unfortunately it is also based solely on ontologies so it provides only limited value for what I’m doing, but it is a valuable resource for understanding and creating visualizations just the same.
Video – Rendering a data cube:
https://www.youtube.com/watch?v=3GvTTVEeEmk
Video – Colliding galaxies:
https://www.youtube.com/watch?v=CPuVfiWLlHI
Universal Constants, Variations and Identities #13 (Knowledge)
Universal Constants, Variations and Identities
#13 Knowledge is what awareness does. (Knowledge)
I’ve published this before elsewhere, but it must be restated now for what is to follow (I’m starting a new octave).
#Knowledge #Wisdom #Understanding #Learning #Insight #Constants #Variances #Metaphysics #Philosophy #MathesisUniversalis #ScientiaUniversalis #PhilosophiaUniversalis #LogicaUniversalis #MetaMathematics #MetaLogic #MetaScience #MetaPhysics #MetaPhilosophy #Awareness
Wonderful Graphics To Save a Disastrous Script
 The ‘Science’ behind the movie ‘Lucy’ cannot hold a candle to the graphics that ‘sell’ that script!
The ‘Science’ behind the movie ‘Lucy’ cannot hold a candle to the graphics that ‘sell’ that script!
A Precise Definition of Knowledge – Knowledge Representation as a Means to Define the Meaning of Meaning Precisely
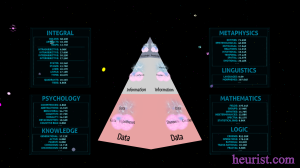
A Precise Definition of Knowledge
Knowledge Representation as a Means to Define the Meaning of Meaning Precisely
Copyright © Carey G. Butler
August 24, 2014
What is this video about?
In this introductory video I would like to explain what knowledge representation is, how to build and apply them. There are basically three phases involved in the process of building a knowledge representation. Acquisition of data (which includes staging), collation and the representation itself. The collation and the representation phases of the process are mentioned here, but I will explain them further in future videos.
You are now watching a simulation of the acquisition phase as it collects and stores preliminary structure from the data it encounters in terms of the vocabulary contained within that data. Acquisition is a necessary prerequisite for the collation phase following it, because the information it creates from the data are used by the collation algorithms which then transform that information into knowledge.
The statistics you are seeing tabulated are only a small subset of those collected in a typical acquisition phase. Each of these counters are being updated in correspondence to the recognition coming from underlying parsers running in the background. Depending upon the computer resources involved in the
acquisition, these parsers may even even run concurrently as is shown in this simulation.
The objects you see moving around in the video are of two different kinds: knowledge fields or knowledge molecules. Those nearest to you are the field representations of the actual data being collected called knowledge fields. They could represent an individual symbol, punctuation, morpheme, lexeme, word, emotion, perspective, or some other unit of information in the data. Each of them contain their own signature – even if their value, state or other intrinsic properties are unknown or indeterminate during the acquisition.
Those farther away from the view are clusters of fields which have already coalesced into groups according to shared dynamically adaptive factors such as similarity, relation, ordinality, cardinality,…
These ‘molecules’ also contain their own set of signatures and may be composed of a mixture of fields, meta-fields and hyper-fields that are unique to all others.The collation phase has the job of assigning these molecules to their preliminary holarchical domains which are then made visible in the resulting knowledge representation. Uniqueness is preserved even if they contain common elements with others in the domain they occupy. Clusters of knowledge molecules and/or fields grouped together are known as ‘knowledge domains’, ‘structural domains’,’dynamical domains’ or ‘resonance domains’, depending upon which of their aspects is being emphasized.
We now need a short introduction to what knowledge representation is in order to explain why you’re seeing these objects here.
What is Knowledge Representation?
Knowledge representation provides all of the ways and means necessary to reliably and consistently conceptualize our world. It helps us navigate landscapes of meaning without losing our way; however, navigational bearing isn’t the only advantage. Knowledge representation aids our recognition of what changes when we change our world or something about ourselves. It does so, because even our own perspective is included in the representation. It can even reveal to us when elements are missing or hidden from our view!
It’s important to remember that knowledge representation is not an end, rather a means or process that makes explicit to us everything we already do with what we come to be aware of. A knowledge representation must be capable of representing knowledge such that it, like a book or other artifact, brings awareness of that knowledge to us. When we do it right, it actually perpetuates our understanding by providing a means for us to recognize, interpret (understand) and utilize the how and what we know as it relates to itself and to us. In fact – knowledge representation even makes it possible to define knowledge precisely!
What Knowledge is not!
Knowledge is not very well understood so I’ll briefly point out some of the reasons why we’ve been unable to precisely define what knowledge is thus far. Humanity has made numerous attempts at defining knowledge. Plato taught that justified truth and belief are required for something to be considered knowledge. Throughout the history of the theory of knowledge (epistemology), others have done their best to add to Plato’s work or create new or more comprehensive definitions in their attempts to ‘contain’ the meaning of meaning (knowledge). All of these efforts have failed for one reason or another. Using truth value and justification as a basis for knowledge or introducing broader definitions or finer classifications can only fail. I will now provide a small set of examples of why this is so.
Truth value is only a value that knowledge may attend. Knowledge can be true or false, justified or unjustified, because knowledge is the meaning of meaning. What about false or fictitious knowledge? Their perfectly valid structure and dynamics are ignored by classifying them as something else than what they are. Differences in culture or language make even make no difference, because the objects being referred to have meaning that transcends language barriers.
Another problem is that knowledge is often thought to be primarily semantics or even ontology based! Both of these cannot be true for many reasons. In the first case (semantics): There already exists knowledge structure and dynamics for objects we cannot or will not yet know. The same is true for objects to which meaning has not yet been assigned,such as ideas, connections and perspectives that we’re not yet aware of or have forgotten. Their meaning is never clear until we’ve become aware of or remember them.
In the second case (ontology): collations that are fed ontological framing are necessarily bound to memory, initial conditions of some kind and/or association in terms of space, time, order, context, relation,… We build whole catalogs, dictionaries and theories about them! Triads, diads, quints, ontology charts, neural networks, semiotics and even the current research in linguistics are examples. Even if an ontology or set of them attempts to represent intrinsic meaning, it can only do so in a descriptive (extrinsic) way.
An ontology, no matter how sophisticated, is incapable of generating the purpose of even its own inception, not to mention the purpose of objects to which it corresponds! The knowledge is not coming from the data itself, it’s always coming from the observer of the data – even if that observer is an algorithm!
Therefore ontology-based semantic analysis can only produce the artifacts of knowledge, such as search results, association to other objects, ‘knowledge graphs’ like Cayley,.. Real knowledge precedes, transcends and includes our conceptions, cognitive processes, perception, communication, reasoning and is more than simply related to our capacity of acknowledgment. In fact knowledge cannot even be completely systematized, it can only be interacted with using ever increasing precision!
- What is knowledge then?
• Knowledge is what awareness does.
• Awareness of some kind and at some level is the only prerequisite for knowledge and is the substrate upon which knowledge is generated.
• Awareness coalesces, interacts with and perpetuates itself in all of its form and function.
• Awareness which resonates (shares dynamics) at, near, or in some kind of harmony (even disharmony) with another tends to associate (disassociate) with that other in some way.
• These requisites of awareness hold true even for objects that are infinite or indeterminate.
• This is why knowledge, the meaning of meaning, can be precisely defined and even provides its own means for doing so.
• Knowledge is, pure and simply: the resonance, structure and dynamics of awareness as it creates and discovers for and of itself.
• Awareness precedes meaning and provides the only fundamentally necessary and sufficient basis for meaning of meaning expressing itself as knowledge.
• Knowledge is the dialog between participants in awareness – even if that dialog appears to be only one-way, incoherent or incomplete.
• Even language, mathematics, philosophy, symbolism, analogy, metaphor and sign systems can all be resolved to this common denominator found at the foundation of each and every one of them.
More information about the objects seen:
The objects on the surface of the pyramid correspond to basic structures denoting some of the basic paradigms that are being used to mine data into information and then collate that information into knowledge. You may notice that their basic structures do not change, only their content does. These paradigms are comprised of contra-positional fields that harmonize with each other so closely that they build complete harmonic structures. Their function is similar to what proteins and enzymes do in our cells.
#Knowledge #Wisdom #Understanding #Learning #Insight #Semantics #Ontology #Epistemology #Philosophy #PhilosophyOfLanguage #PhilosophyOfMind #Cognition #OrganicIntelligence #ArtificialIntelligence #OI #AI
#Awareness
Things Are NOT As They Should Be

(click picture to show the video)
We are being fed disinformation telling us that we never had privacy and to get used to this new ‘environment’. We must reject this false set of memes!
If you think you have nothing to hide, think again! What if someone you love and cherish does have something to hide and the watchers frame you for being related to them? If they can watch your every move and thought, then they can replace them as well and say it was you!
We are in a whole new ball game of spying – watch and see!
It’s Called a Knowledge Graph, but It Makes Nice Pictures

When did association amount to real knowledge?
Am I the only one to recognize something’s wrong with this picture?
An Organically Universal Frame of Mind Arises

As if it were a ‘combination lock’, if we begin to ask the right questions… the ‘tumblers’ move…
http://humansarefree.com/2011/05/lets-illuminate-and-dream-awake.html
UPDATE: http://www.istockphoto.com/video/world-network-20381126 (an attractive representation of data)
Putting Knowledge Back Into the Hands of the People

(click picture to show the website)
Currently 1.68 TB (as of this date) of research data available!
The free exchange of ideas… again!
Intel Announces Edison, A Computer the Size Of An SD Card

(click picture to show the article)
Why aren’t we discovering and creating ourselves rather than pay corporations to create things that are going to replace us? Something is really wrong here.
We are creating a nightmare when we could have a wonderful dream made reality.
The name Edison is fitting (if you know how Edison treated Tesla.)
Google Semantic Search – David Amerland

What is Semantic Search?
The first thing I notice is the fluid, direct and economical style of writing that makes reading the book a pleasant experience.
1 Definition found: Search, above all else, is marketing.
The Shift to Semantic Search
I disagree with the addage “Knowledge is power!” For me, the use of knowledge is what can be or manifests power. David’s proviso that “knowledge is power if it leads to comprehension” pleases me, because it comes closer to what knowledge is, as it relates to power.
2 Definitions found: Semantics, Tim Berners-Lee’s ‘Semantic Search’
At one point David refers to how an answer engine’s success, as well as Google’s brand, depends upon the answers it provides; I would include other critical factors having nothing to do with the answers the engine returns. Google’s reputation is already in question in meaningful circles, despite the usefulness of its algorithms. I suspect that David will address at least some of them as the book continues.
How Search Works
Definitions: Spiders, Index, SERPs, organic results, ranking elements (algorithm/signals).
Clarifications:
How Google’s page is synthesized from an interplay of elements composed of front and back ends.
The incredible speed and volume of indexing data is touched on.
Where the system no longer works as it was intended (SEO gaming) and how semantic search has changed that.
I like the use of the term ‘signals’ (a characteristic of knowledge) with respect to ranking. I’m looking forward to a clearer understanding of what that entails as it relates to semantic search.
How Semantic Search Works
Definitions: URI, RDF, (semantic) ontologies, serendipity discovery (and the dynamics that govern it)
Clarifications:
Requirements that semantic search must be supplied to understand words (URI, RDF, ontology library)
Learning more about serendipity discovery interests me, however at this point in the text, only its usefulness in marketing and finding customers in the future is discussed. There is mention, however, that the book formalizes a set of practices to use it.
I am looking forward to an explanation of why serendipity discovery is treated in this ‘condensed’ way. David offers a bibliography for those who need a deeper understanding.
I am concerned on one other point: the restriction of semantics solely to an ontological foundation. I am aware at this point that an interplay of 2 additional components (and their surrounding dynamics) are in use (URI and RDF), but I need to know more about them, before I am willing to trust them completely.
It is important to remember that up to this point no promise is made for _real_ understanding in the model presented, rather only its _simulation._ That seems to be, nevertheless, very useful and completely new.
Grady Booch: The Human and Ethical Aspects of Big Data

(click picture to show the video)
Important questions we should be answering now… not later. Important examples throughout modern history and where it influences and is influenced by it.

Morphological Resonance Driven Analysis And Sythesis
 (click picture to show the video)
(click picture to show the video)
Big Data’s Promise and Limitations

(click on picture to show the article)
